
반응형
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- ReactNative
- Android
- localserver
- VirtualBox
- 맥
- 오블완
- MAC
- 네트워크
- IOS
- react
- 티스토리챌린지
- 개발
- xcode
- 리눅스
- linux
- webpack
- build
- MachineLearning
- Chrome
- PYTHON
- 센토스
- fastapi
- centos
- pydantic
- TensorFlow
- androidstudio
- node
- unittest
- vsCode
Archives
- Today
- Total
로메오의 블로그
[TensorFlow] 매출 예측하기 - 선형회귀 Linear Regression 본문
반응형
독일 빵집이라는 곳에서 영업시간에 따른 매출이 아래와 같다고 가정해보겠습니다.
| 영업시간 | 매출 |
| 1 | 9,500 |
| 2 | 11,000 |
| 3 | 19,500 |
| 4 | 28,000 |
| 5 | 42,500 |
| 6 | 51,000 |
| 7 | 60,000 |
| 8 | 75,000 |
| 9 | 86,500 |
그럼 10시간 영업했을때 매출은 얼마쯤 될까요?
선형회귀 모델을 구축하겠습니다.
가설 Hypothesis

H (Hypothesis): 가설
W (Weight): 기울기
b (bias): Y절편
머신러닝은 W와 b값을 계속 수정해나가면서 가장 합리적인 H 값을 찾는 과정입니다.
비용 Cost
가설이 얼마나 정확한지 판단하는 기준

비용은 직선과의 거리를 계산해서 구할수 있습니다.
비용함수 Cost Function

비용함수는 예측값에서 실제값을 뺀 제곱의 평균을 계산해서 구할수 있습니다.
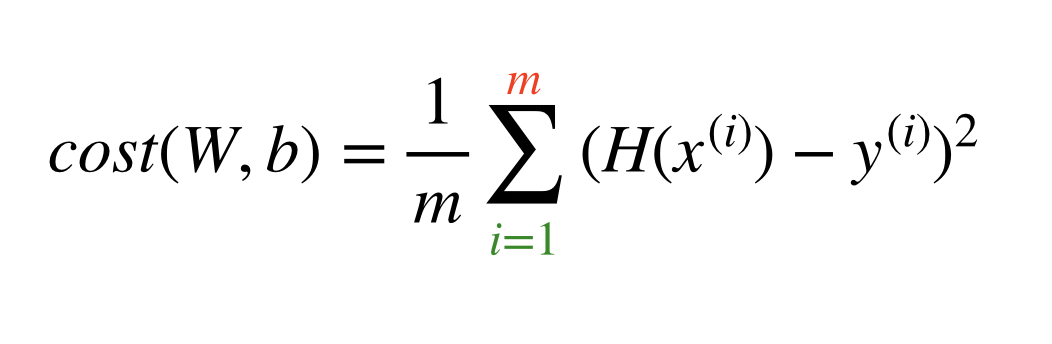
경사하강 Gradient Descent

위 가설 Hypothesis 식에서 절편을 제거해서 식을 간단하게 만들어 줍니다.
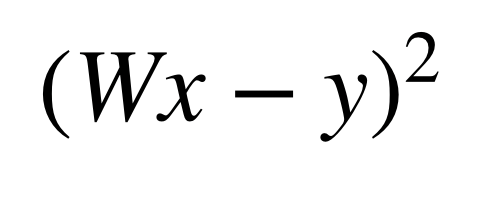
비용함수는 위와 같이 되고, 아래와 같은 그래프로 표현할 수 있습니다.

미분과 기울기

미분을 이용해서 기울기를 구하게 됩니다.
곡선의 가장 깊은 골자기는 기울기가 0이 되고, 이때 가장 좋은 식이라 평가합니다.
즉 경사회귀는 곡선의 기울기를 타고 내려가서 기울기가 0이 되는 지점을 찾는 알고리즘입니다.

응용프로그램 > Python 3.7 > IDLE.app을 실행합니다.
File > New File을 실행합니다.
프로그램 작성
import tensorflow as tf
dataX = [1, 2, 3, 4, 5, 6, 7, 8, 9]
dataY = [9500, 11000, 19500, 28000, 42500, 51000, 60000, 75000, 86500]
weight = tf.Variable(tf.random.uniform([1], -100, 100))
bias = tf.Variable(tf.random.uniform([1], -100, 100))
X = tf.compat.v1.placeholder(tf.float32)
Y = tf.compat.v1.placeholder(tf.float32)
hypothesis = weight * X + bias
cost = tf.reduce_mean(tf.square(hypothesis - Y))
jump = tf.Variable(0.01)
optimizer = tf.compat.v1.train.GradientDescentOptimizer(jump)
train = optimizer.minimize(cost)
init = tf.compat.v1.global_variables_initializer()
session = tf.compat.v1.Session()
session.run(init)
for i in range(5001):
session.run(train, feed_dict={X: dataX, Y: dataY})
if i % 500 == 0:
print (i, session.run(cost, feed_dict={X: dataX, Y: dataY}), session.run(weight), session.run(bias))
print(session.run(hypothesis, feed_dict={X: [10]}))
## tensorflow 라이브러리를 import 하서 tf로 별칭한다.
import tensorflow as tf
## X측 데이터에 엽업시간을 입력한다.
dataX = [1, 2, 3, 4, 5, 6, 7, 8, 9]
## Y축 데이터를 매출을 입력한다.
dataY = [9500, 11000, 19500, 28000, 42500, 51000, 60000, 75000, 86500]
## 가설의 기울기(Weight: 가중치)를 -100 ~ 100의 랜덤값으로 넣어준다.
weight = tf.Variable(tf.random.uniform([1], -100, 100))
## y절편(bias: 치우침)을 -100 ~ 100의 랜덤값으로 넣어준다.
bias = tf.Variable(tf.random.uniform([1], -100, 100))
## X, Y placeholer(실제값) 설정
X = tf.compat.v1.placeholder(tf.float32)
Y = tf.compat.v1.placeholder(tf.float32)
## 가설(예측값)을 설정한다.
hypothesis = weight * X + bias
## 비용을 설정한다. (예측값 - 실제값)을 제곱해서 평균값을 산정한다. (-> 마이너스(-)가 나오지 않음)
cost = tf.reduce_mean(tf.square(hypothesis - Y))
## 경사하강 알고리즘에서 점프값을 설정한다.
jump = tf.Variable(0.01)
## 경사하강 라이브러리에 점프값을 넣어준다.
optimizer = tf.compat.v1.train.GradientDescentOptimizer(jump)
## 최소비용으로 학습할수 있도록 비용을 설정한다.
train = optimizer.minimize(cost)
## 변수초기화
init = tf.compat.v1.global_variables_initializer()
## 세션설정
session = tf.compat.v1.Session()
## 세션 초기화
session.run(init)
## 5000번 반복해서 학습시키기
for i in range(5001):
## dataX, dataY를 넣어서 학습시킨다.
session.run(train, feed_dict={X: dataX, Y: dataY})
## 500번에 한번식 log를 출력한다.
if i % 500 == 0:
## 출력값 (횟수, 값, 가중치(기울기), y절편)
print (i, session.run(cost, feed_dict={X: dataX, Y: dataY}), session.run(weight), session.run(bias))
## 예측값을 주어 결과를 출력한다.
print(session.run(hypothesis, feed_dict={X: [10]}))
프로그램 실행

Run > Run Module 을 실행합니다.
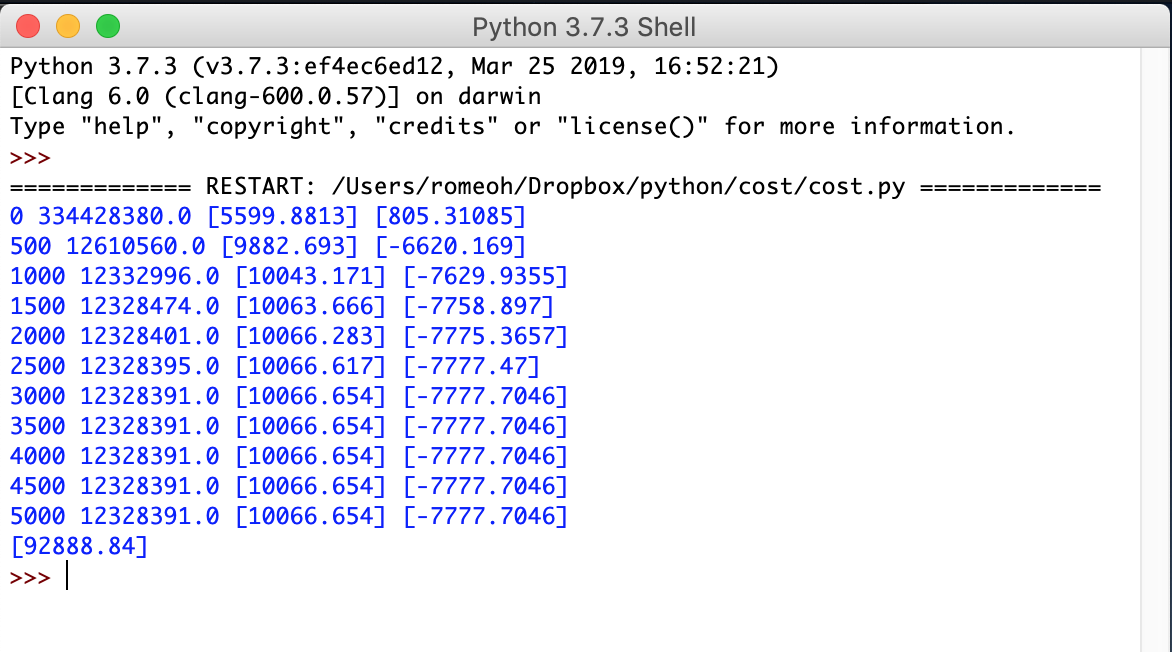
10시간 영업 시 92,888.84 원의 매출을 올리는 것으로 예측합니다.
학습 초기에는 값의 변화가 크지만, 3000번 이상 학습을 하면 가중치 등 값의 변화가 거의 없는 것을 알 수 있습니다.
반응형
'Backend > Python & Blockchain' 카테고리의 다른 글
| [Ethereum] 나만의 코인 발행하기 ETH - ICO (0) | 2019.07.03 |
|---|---|
| [Ethereum] MetaMask 테스트 넷에서 무료코인 받기 (0) | 2019.07.03 |
| [Ethereum] 메타마스크 설치 [Metamask - 여우지갑] (0) | 2019.07.03 |
| [TensorFlow] 설치하기 (0) | 2019.06.26 |
| [Python] Python 3.7 설치하기 - 업그레이드 (MacOSX) (0) | 2019.06.26 |
'Backend/Python & Blockchain' Related Articles
more




Comments